

One of the biggest trends in recent years has been the large-scale adoption and application of big data technologies, with many organisations exploring how best they can utilise new and previously untapped data sources to provide meaningful business insights and support strategic decision making.
When an organisation is first looking to implement a big data platform, we often receive questions around the role of a big data solution compared against an organisation’s existing data warehouse, and whether one can be considered a replacement for the other.
On an architectural level, looking at the structures involved in data loading, this comes down to the difference between big data’s data lake and a data warehouse’s staging layer, so it is worth exploring both in more detail to better understand how and why they are used.
What is a data lake?
A data lake is a large collection of both structured (ie, transactional, relational) and unstructured (ie, audio, video, social media) data, which could include all data available in an organisation, stored in its raw format.
The raw data is then accessed using a schema on read (ie, applying structure to the data as it is read) approach, also known as ELT (extract-load-transform), in which the business logic and data transformation is applied when accessing the data, and is often done on an ad-hoc basis.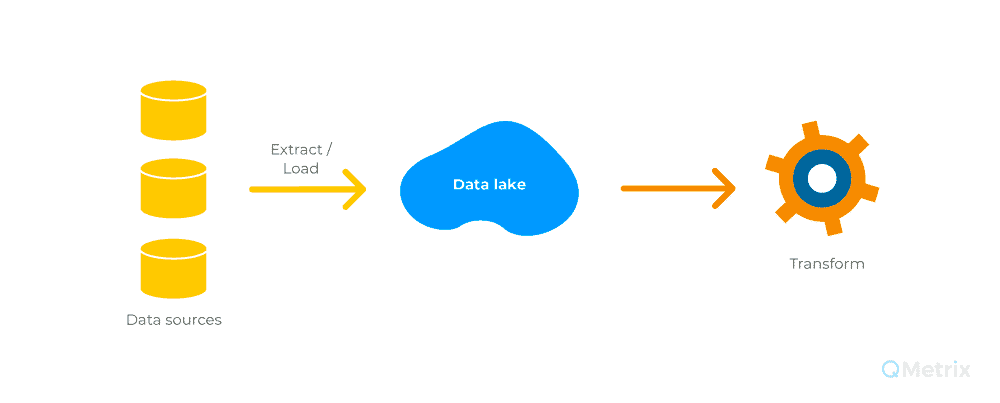 A data lake provides the ability to load and store a wide variety of data as-is and can be accessed on demand for various uses including advanced analytics, machine learning, and data mining amongst others.
A data lake provides the ability to load and store a wide variety of data as-is and can be accessed on demand for various uses including advanced analytics, machine learning, and data mining amongst others.
What is a staging layer?
A staging layer consists of selected structured data that is transformed before being loaded to the data warehouse in a pre-defined format.
Compared to schema on read used by the data lake, the staging layer uses a schema on write approach (ie, applying structure to the data as it is written), otherwise known as ETL (extract-transform-load), where business logic and transformations are developed prior to loading and are updated when needed.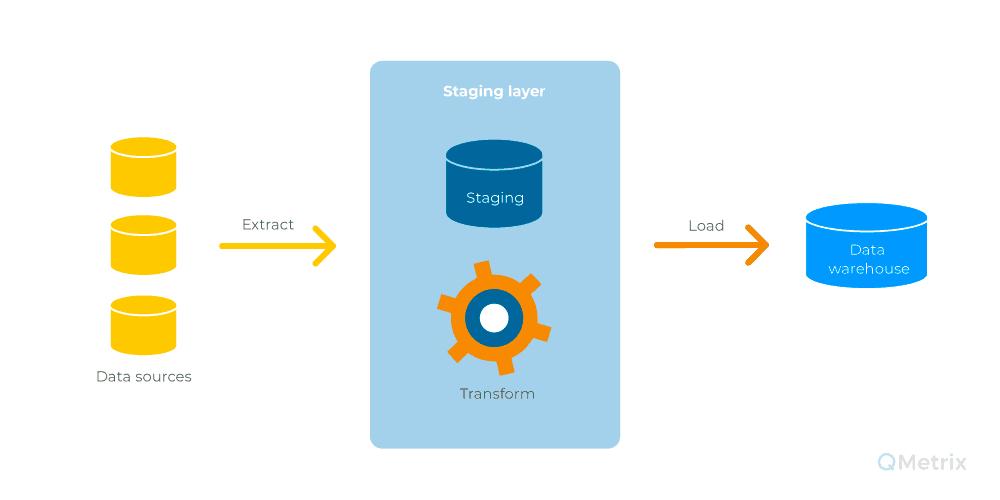 A staging layer provides a closed off area for the loading and processing of source data, and is used as a workspace for subsequently applying transformations including complex calculations, data cleansing, and change data capture, before the data is loaded to the data warehouse for analysis.
A staging layer provides a closed off area for the loading and processing of source data, and is used as a workspace for subsequently applying transformations including complex calculations, data cleansing, and change data capture, before the data is loaded to the data warehouse for analysis.
Differences in development
The schema on read approach lends itself to shorter development timeframes due to the ad-hoc nature of data access, while the schema on write approach has a slower time to delivery by relative comparison as it takes longer to create and test the necessary load logic and data objects.
Ad-hoc access in a data lake can increase the chances of repetition of logic occurring where multiple users independently create similar or overlapping datasets. This repetition can lead to both a reduction in accuracy and a duplication of effort, as well as the creation of data silos due to an absence of conformed dimensions.
In comparison, a staging layer will tend to have a higher level of accuracy and minimal duplication of effort as development of a dataset is typically only done once, following an agreed upon set of business rules and with the resulting calculations and transformations generally accepted as being correct.
Differences in users and security
There are also differences in the types of users for each system. A data lake is typically accessed by data scientists as well as more advanced data analysts from a variety of business areas, developing standalone solutions for advanced analytics, data mining, and machine learning, as well as other downstream business processes.
To get the most benefit from the wide variety of data available in the lake, there is often zero or minimal security applied on the data that the data scientists and analysts are able to access, which feeds back into the possibility of decreased accuracy and duplication of effort.
A staging layer is usually only accessed by warehouse developers with the single purpose of populating conformed and delivering “single source of truth” into the data warehouse. The populated data warehouse is then made widely available throughout the organisation. The developers should have the required security access across the whole staging layer, but the data coming out of staging may be locked down to specific business areas or security roles.
Do you need a data lake or staging layer?
In summary, a data lake allows fast access to diverse sets of data in a single location but comes with accuracy, effort and security considerations. On the other hand, a staging layer is more tightly controlled and requires longer development time, but has the benefit of increased accuracy and trust in the data warehouse.
Given the differences in structure and how fit-for-purpose a data lake and a staging layer are, it would generally seem that one wouldn’t easily replace another.
There is the possibility of integrating one into the other. A data lake could be used as the source for staging layer data, or a data warehouse (though not the staging layer) could be included in the data available in a data lake.
That said, if there is a business case to replace, combine, or integrate the two then time should be taken to carefully consider the implementation and any possible impact, and is probably best looked at on a case by case basis.
Considering a big data platform? QMetrix can look into your existing structures and business objectives, then advise on best practise and implement for you. Contact us to discuss.







